
0x00
最近夏小墨看上了一部漫画《妖精种植手册》,嗯,一部还行的后宫漫画,夏小墨觉得还不错,准备全部下载回来存着,然鹅这漫画更新了快400话,平均一话10页,要是一页一页手动保存,想想都可怕……最终,夏小墨决定使用node来批量下载,虽然中间走了不少弯路,但至少成功地把漫画下载了回来。所以,简单记录下过程,当然,隔了几天,难免有些遗漏,望见谅。在后续中,你将看到以下内容:
- request请求
- cheerio解析网页
- fs读写文件
- iconv-lite对gb2312进行转码
- phantom加载网页
- download下载图片
由于夏小墨始终掌握不了 promise 或 async/await 的使用方法,所以目前均采用回调的方法,望大佬们轻喷……
0x01
要下载,首先要找到目标,经过筛选,夏小墨决定对下面这个地址下手,对不起了~~截图如下
http://m.pufei.net/manhua/244/
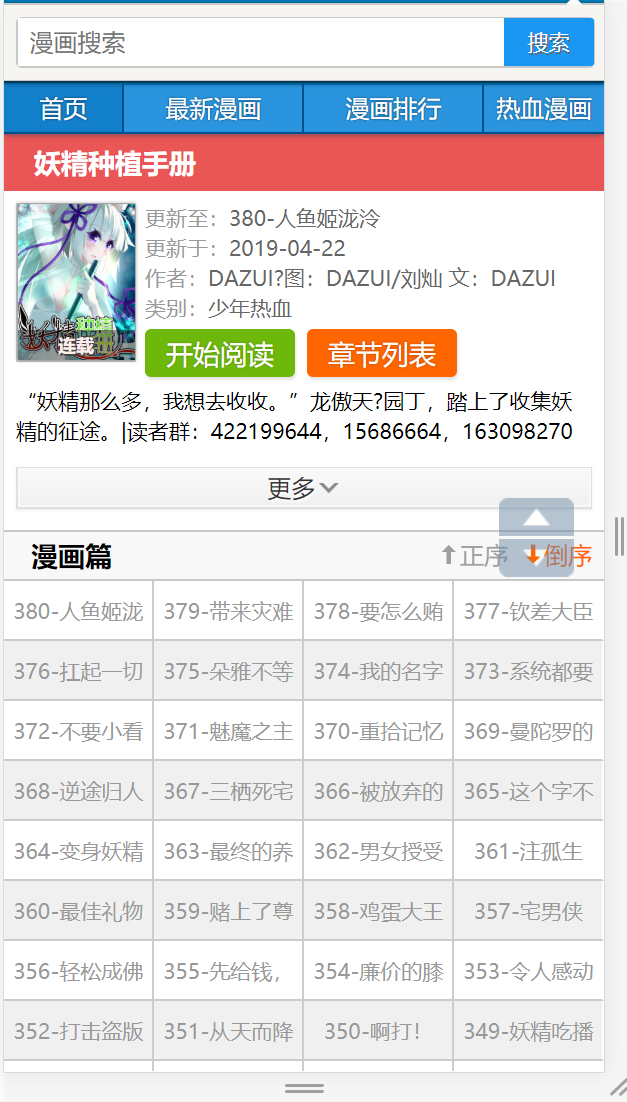
按F12打开控制台简单分析下页面

发现每一话都是一个li,里面包含一个a标签,但是在链接上面却没啥特别的规律,也懒得找规律了,直接全取出来保存个文件算了,开干
首先请求获取整个页面,这里使用request请求库,在node下常用发请求库,使用方法如下:
1
2
3
4
| const request = require('request');
request({url: url}, (err, res, body) => {
console.log(body);//body就是页面内容
})
|
拿到页面后,就可以解析内容了,取出我们想要的内容,使用cheerio库,方法如下:
1
2
3
4
| const request = require('request');
let $ = cheerio.load(body); //$就是页面了,之后就可以像使用jquery一样用选择器选出想要的内容,也可以修改相应的值
//例如取出所有的li,并统计数量
console.log($('li').length);
|
这时候理论上应该没问题了,只要取出所有的li,再把每个li里的a标签取出来,获得a标签的href和title属性就可以了,事实上也的确是这样。只是在尝试打印内容的时候,发现中文都无法显示,全部是方块。检查后发现,网页是gb2312编码,而node是不支持的……这时候祭出iconv-lite来转码
1
2
3
4
5
6
| const iconv = require('iconv-lite');
//由于request默认会转码成utf-8,这时候用iconv-lite转码是没用的,所以要去掉转码
request({encoding: null,url: url}, (err, res, body) => {
console.log(body);//body就是页面内容
let bodyString = iconv.decode(body, 'gb2312').toString(); //注意decode 的第二个参数为转码前的编码格式
})
|
接下来使用数组保存所有链接和标题,最后转成字符串保存文件就可以了,保存文件使用node的fs,保存方法如下:
1
2
3
4
5
6
7
| fs.writeFile('urls.txt', JSON.stringify(urls), err => {
if (err) {
return console.log(err);
}else{
console.log("成功");
}
})
|
最后,完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| //获取所有链接地址 已完成
const getAllUrls = () => {
request({
encoding: null,
url: "http://m.pufei.net/manhua/244/"
}, (err, res, body) => {
let bodyString = iconv.decode(body, 'gb2312').toString();
let $ = cheerio.load(bodyString)
let urls = [];
console.log($('li').length);
$('li').each((i, e) => {
try {
let chap = {};
chap.title = e.children[0].attribs.title;
chap.url = e.children[0].attribs.href;
urls.push(chap);
} catch (e) {} finally {}
})
fs.writeFile('urls.txt', JSON.stringify(urls), err => {
if (err) {
return console.log(err);
}
console.log("成功");
})
})
}
|
至此,成功获得所有的url和标题

0x02
有了每一话的地址后,随便打开一话的某一页:
http://m.pufei.net/manhua/244/199094.html?af=2
可以看到链接前面部分就是之前获取的链接,而后面的参数af则表示第几页,因此,接下来需要获取每一话共有多少页。老样子,开控制台,找到页码:
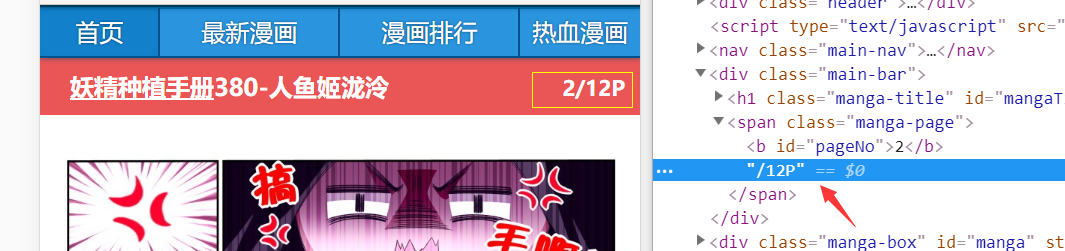
如图所示,依然使用request获取页面,cheerio解析,获取页码,由于页码两边还有其他字符,所以用正则处理下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| //获取页码
const getPageNum = (url) => {
let options = {
url: url
}
request(options, (err, res, body) => {
if (err) {
console.log("获取页码请求出错");
} else {
let $ = cheerio.load(body)
let num = 0;
try {
num = $('.manga-page').children().get(0).next.data;
num = num.replace(/[^0-9]/ig, "");
console.log("页数:" + num);
} catch (e) {
console.log(e);
}
}
})
}
|
0x03
循环获得每一话的页码之后,接下来每一话需要再来个循环,获取到每一页的图片地址,然后再通过图片地址下载回来保存就行了,考虑到图片有点多,所以夏小墨准备每一话建一个文件夹。建文件夹的方法如下:
1
2
3
4
5
6
7
| fs.mkdir(foldPath, (err) => {
if (err) {
console.log("创建文件夹出错");
}else{
console.log("创建文件夹成功");
}
})
|
文件夹建好之后,循环走起,在这里,先通过文件名判断了一下这张图片是否存在,存在了就直接跳过不下载,减少不必要的请求:
1
2
3
4
5
6
7
8
9
10
11
12
| for (let i = 1; i <= num; i++) {
let imgPageUrl = url + "?af=" + i;
let namePath = foldPath + "/" + i + ".jpg"
fs.access(namePath, err => {
if (err) {
console.log(namePath + "文件不存在")
getImgUrl1(imgPageUrl, i, foldPath); //这里去请求页面获取地址
} else {
console.log(namePath + "文件已存在,跳过")
}
})
}
|
0x04
用同样的方法获取图片地址:
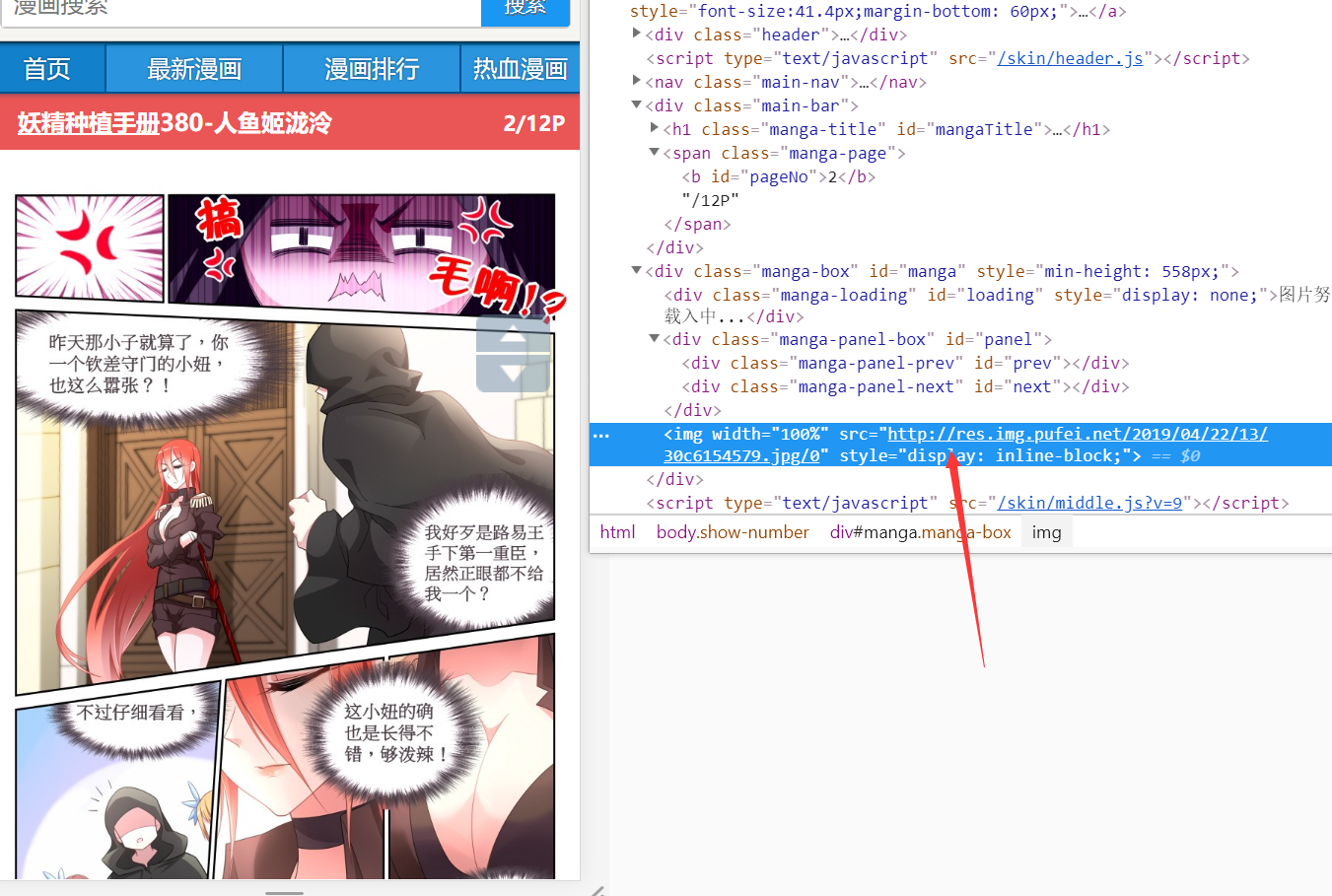
这时候,理论上只要获得.manga-panel-box 或者 #panel,再取得这个元素下的img标签就可以了,可这时候却死活获取不到。直接打印request返回的完整页面,panel下发现并没有img标签,也就是说,这个img标签是通过js另外加载的……
既然这样,首先想到的是看看js代码有没有线索,然而,压缩过后的js真的很难看懂,遂放弃。然后发现这个网站有个app,可能会有线索,遂下载回来安装,抓包看请求(如果需要抓包的教程,另外再写了,不过这个随便搜搜就有了),成功获取到请求,能得到一话的所有图片地址,只是请求这个接口的时候有个签名校验,反编译代码后发现是md5,且成功获得盐,然而不知道原字符串的拼接方式,尝试了几次无法猜出,只能放弃。
那么就没有办法了么?经过一番搜索后,发现了phantomJs。简单点,可以把他理解为一个隐形的浏览器,没有界面的浏览器,但是我们可以像正常的浏览器一样操作他。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| const phantom = require('phantom');
const getImgUrl1 = (url) => {
console.log("请求页面-->" + url);
let sitePage = null;
let phInstance = null;
phantom.create().then(instance => {
phInstance = instance
return instance.createPage()
}).then(page => {
sitePage = page;
return page.open(url);
}).then(status => {
console.log(status); //获取结果状态
return sitePage.property('content'); //获取相应的属性内容
}).then(content => {
console.log(content);
}).catch(error => {
console.log(error);
phInstance.exit();
});
}
|
然而,这时候发现phantom始终获取不到整个页面,遂在page上添加请求监听:
1
2
3
| page.on("onResourceRequested", function(requestData) {
console.info('Requesting', requestData.url)
});
|
发现在page请求图片的时候卡住了,既然这样,反正只要取得图片链接就可以了,在哪取到都一样,因此,在取得链接后直接保存链接,然后直接退出phantom,毕竟开多了内存会吃不消的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| const fs = require('fs');
const phantom = require('phantom');
let dataString = fs.readFileSync('urlsnew.txt'); //读取全部的地址,标题等
let dataArray = JSON.parse(dataString);
const getChapUrl = (index) => {
console.log("------->" + index);
let url = baseUrl + dataArray[index].url
let title = dataArray[index].title
let num = dataArray[index].num
console.log(title);
console.log(url);
console.log(num);
let urlArray = JSON.parse(fs.readFileSync('urls/' + title + '.txt'));
for (let i = 1; i <= num; i++) {
//判断这一页的地址是否已经取得
//因为不能一次保证全部取得,所以需要跑个两次左右
if (urlArray[i - 1] == undefined || urlArray[i - 1] == null) {
let imgPageUrl = url + "?af=" + i;
console.log("请求页面-->" + imgPageUrl);
let sitePage = null;
let phInstance = null;
let saved = false
try {
phantom.create().then(instance => {
phInstance = instance
return instance.createPage()
}).then(page => {
sitePage = page;
page.on("onResourceRequested", function(requestData) {
//console.info('Requesting', requestData.url)
if (requestData.url.indexOf("http://res.img.pufei.net") != -1) {
if (!saved) {
saved = true
console.log("图片地址:" + requestData.url);
let urltemp = requestData.url;
urlArray[i - 1] = urltemp;
fs.writeFile("urls/" + title + '.txt', JSON.stringify(urlArray), err => {
if (err) {
return console.log(err);
}
console.log(title + "文件写入成功");
})
}
phInstance.exit();
}
});
return page.open(imgPageUrl);
}).then(status => {
console.log(status); //获取结果状态
return sitePage.property('content'); //获取相应的属性内容
}).then(content => {
console.log(content);
phInstance.exit();
}).catch(error => {
console.log(error);
phInstance.exit();
});
} catch (e) {
console.log(err);
}
}
}
}
|
循环跑了两遍后,基本把全部地址都取了出来:
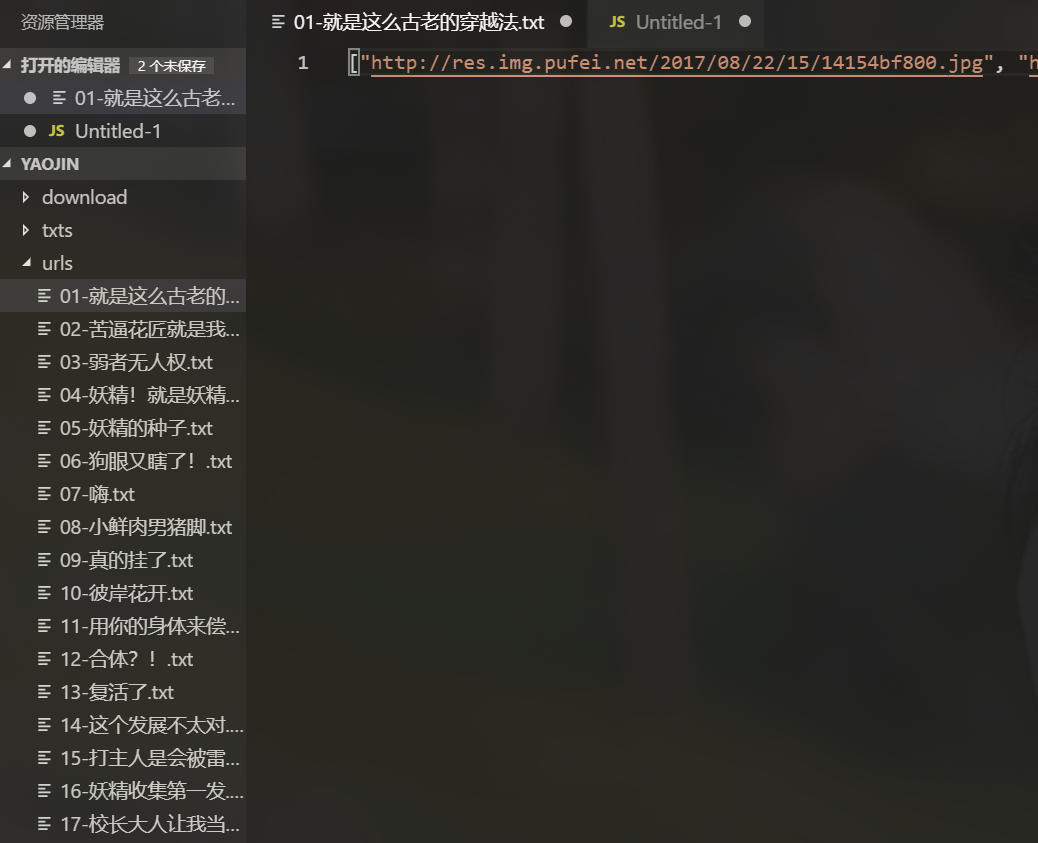
这里我另外写了个循环判断是否还有null的地址,顺便统计了下数量,就不放代码了
0x05
有了图片地址,接下来就好办了,用download下载就可以了,如下:
1
2
3
4
5
6
7
8
9
| const download = require('download');
const downloadsaveImg = (url, num, path, index) => {
console.log(url);
download(url).then(data => {
let name = path + "/" + num + ".jpg";
fs.writeFileSync(name, data);
console.log("保存成功" + name);
});
}
|
继续循环跑起来,最终获得整部漫画……
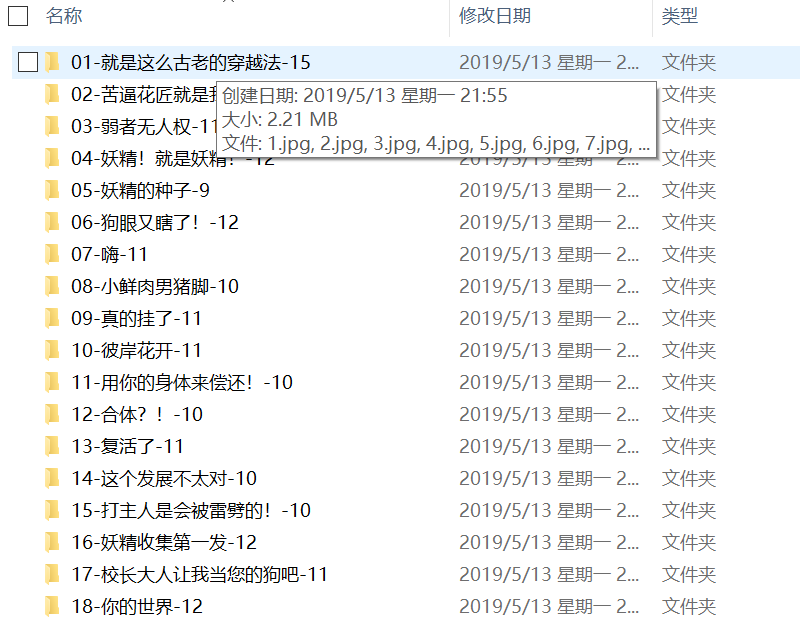
0x06
正常情况到这里应该就结束了,然而在最后统计下载回来的数量的时候,发现与之前统计链接的数量对不上了,检查后发现少了两话,手动访问页面,发现这破网站丢了这两话的图片,身为强迫症患者只能到别处去找,最终,在下面这个地址上找到了:
https://m.manhualou.com/manhua/4773/
进一步查看后,发现,这个网站能通过request直接取得图片链接……
一口老血……合着之前那么麻烦全都白费了……
最后,给出完整的通过manhualou下载的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
| const cheerio = require('cheerio');
const request = require('request');
const fs = require('fs');
const download = require('download');
let dataString = fs.readFileSync('urls.txt');
let dataArray = JSON.parse(dataString);
console.log(dataArray.length);
//获取所有链接地址 已完成
const getAllUrls = () => {
request({
url: "https://m.manhualou.com/manhua/4773/"
}, (err, res, body) => {
let $ = cheerio.load(body)
let urls = [];
$('.Drama.autoHeight').children('li').each((i, e) => {
try {
let chap = {};
chap.title = e.children[1].children[1].children[0].data;
chap.url = e.children[1].attribs.href;
urls.push(chap);
} catch (e) {} finally {}
})
fs.writeFile('urls.txt', JSON.stringify(urls), err => {
if (err) {
return console.log(err);
}
console.log("成功");
})
})
}
const getPageNum = (i) => {
console.log("-------");
let chapData = dataArray[i];
let url = chapData.url
let title = chapData.title
console.log(title);
console.log(url);
let options = {
url: url
}
request(options, (err, res, body) => {
if (err) {
console.log("获取页码请求出错");
} else {
let $ = cheerio.load(body)
let num = 0;
try {
num = $('#k_total').get(0).children[0].data;
console.log("页数:" + num);
let foldPath = 'download/' + title + "-" + num
fs.mkdir(foldPath, (err) => {
if (err) {
console.log("创建文件夹出错");
}
console.log("创建文件夹成功");
let tempUrl = url.substring(0, url.length - 5)
for (let i = 1; i <= num; i++) {
let imgPageUrl = tempUrl + "-" + i + ".html";
let namePath = foldPath + "/" + i + ".jpg"
console.log(imgPageUrl);
fs.access(namePath, err => {
if (err) {
console.log(namePath + "文件不存在")
getImgUrl(imgPageUrl, i, foldPath);
} else {
console.log(namePath + "文件已存在,跳过")
}
})
}
})
} catch (e) {
console.log(e);
}
}
})
}
const getImgUrl = (imgUrl, i, foldPath) => {
let options = {
url: imgUrl
}
request(options, (err, res, body) => {
if (err) {
console.log("获取页面请求出错");
} else {
let $ = cheerio.load(body)
let detailImgUrl = $('mip-img').get(0).attribs.src
console.log(detailImgUrl);
saveImg(detailImgUrl,i,foldPath)
}
})
}
const saveImg = (url, num, path) => {
download(url).then(data => {
let name = path + "/" + num + ".jpg";
fs.writeFileSync(name, data);
console.log("保存成功" + name);
});
}
const downloadTask = ()=>{
let i = 386;
let timeId = setInterval(() => {
i++;
if (i == 388)
clearInterval(timeId);
getPageNum(i);
}, 5000);
}
downloadTask();
//getPageNum(5)
//getAllUrls();
|

 wechat
wechat alipay
alipay











